
Personal Note from the Editor, Patrick:
Hi there, beautiful to see you!
A quick question: how long is your average conversation with ChatGPT?
A single query to a large language model (LLM) consumes between 0.5 and 50 Wh, releasing 1–5 grams of CO₂.
That’s ≈10 times more than for a conventional (“old-school”) Google search. But what does that mean for us scientists?
Reducing Our Impacts
According to Lannelongue et al., training AlphaFold took 11 days and emitted approximately 3.92 tons of CO₂e.
And each time it predicts the structure of a protein with 2,500 residues, it adds another 3 kg CO₂e.
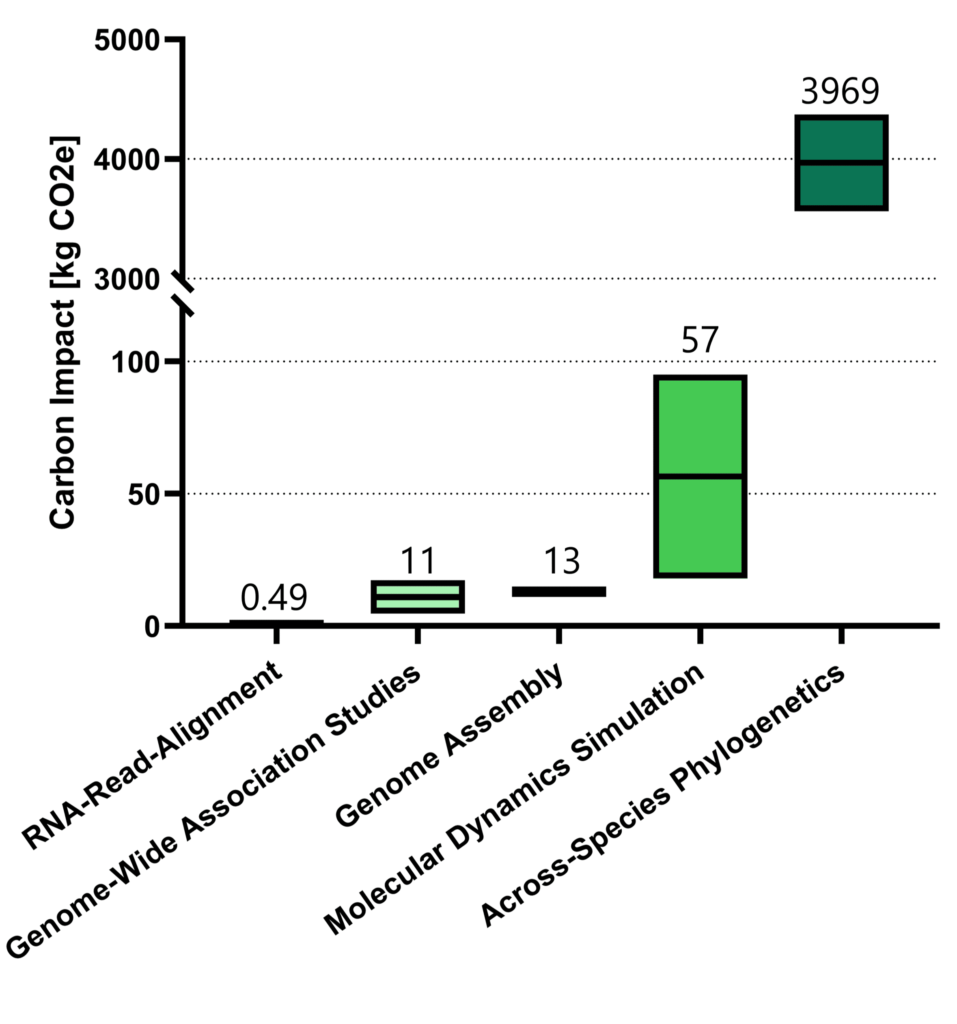
This isn’t just limited to biology. For comparison, the telescopic research station in Hawaii produces an estimated 749 tons of CO₂e every year—mostly for research purposes. So how can we reduce our footprint?
Reduction – Handle AI with Care
We saw that a single ChatGPT prompt uses, on average, 10 times more energy than a Google search.
Generating a picture with DALL·E or Midjourney can consume between 0.5–1 kWh, translating to 100–400 grams of CO₂ emissions.
Therefore, when it comes to simple questions—like protein sizes or chemical formulas—you might be better off searching in UniProt or Wikipedia.
If you use Large Language Models (LLMs) like ChatGPT, optimizing your prompts can make a difference.
For example, under standardized testing conditions:
- Using “justify” in your prompt leads to 20–60% higher energy consumption than using “explain.”
- Replacing “explain” with “list” can save another 10–30% of electricity.
Although a study by Adamska et al. suggests that prompt length has limited influence on energy use, response length is linearly correlated with consumption.

However, here are three habits that make your AI usage more efficient:
- Be specific from the start. Give ChatGPT all relevant information upfront—style, tone, structure—so you don’t need multiple refinements. For other models, double-check settings for data fidelity, boundary conditions, or accuracy.
- Reuse what you’ve already created. Provide ChatGPT with previous content or data to build upon instead of starting from scratch.
- Interrupt bad generations early. If the response doesn’t match your intent, stop it immediately. Also, clean up conversations you no longer need.
Using Services & Storing Data
In March 2020, DE-CIX in Frankfurt—the world’s largest internet exchange point—recorded a throughput peak of 9.16 terabits per second.
That’s equivalent to more than two million HD videos being transmitted simultaneously.
Moreover, storing 1,000 GB of data in data centers can generate 100–300 kg of CO₂ per year. That’s 20–50 watts per terabyte—continuously.
(The nitty gritty of how optimized networks can reduce energy use by 30–95% you can read in our free Slack Channel).
Therefore:
- Edit and store documents locally. If you don’t need real-time collaboration, use a local text editor instead of cloud-based tools like Google Docs or iCloud Pages.
- Save AI outputs locally. For example, if you use Copilot or ChatGPT to summarize a paper, paste the summary into your Word file or citation manager. This avoids repeating the same energy-intensive queries.
- Download and organize data. After generating AI responses or images, save them on your device rather than leaving them in the cloud.
Knowing the Limits of AI
ChatGPT performs well at explaining statistical concepts but is often unreliable for actually performing calculations. For that, you’re better off using dedicated statistical software.
How to test and validate:
- A) Start small. Run test prompts or calculations on limited datasets to evaluate performance.
- B) Break tasks into steps. Divide large requests into manageable chunks—so if something fails, you don’t need to rerun everything.
- C) Reuse working prompts. When something works well, save it. From there, develop a prompt-engineering strategy (aka remember what patterns work )
Getting the Time Right
Electricity grids fluctuate in carbon intensity throughout the day, depending on demand and the availability of renewables like solar and wind.
According to Dodge et al., if you time your bioinformatics jobs strategically:
- Shifting start times by just a few hours can cut emissions by up to 80% for short jobs (<30 minutes). For longer jobs (>1 day), shifting often saves less than 1.5%.
- Suspend and resume. For long jobs, pausing during carbon-intensive hours and resuming during greener periods can reduce emissions by up to 25%.
You can find some additional actions to reduce impacts in our free Slack of you like.
Applying The Knowledge
Don’t shy away from AI for fear of its environmental impact.
AI is here to stay—and it can play a key role in improving science.
But when using AI, ask yourself:
- What | Which model or service are you using?
- How | Can you optimize your prompt or setup?
- When | Can you run jobs during low-carbon hours?
- Where | Can you store data locally?
- Why | Do you really need AI for this task?
A good rule of thumb to reduce your impact: keep computation times as short as possible.
That means optimizing prompts, double-checking settings, and planning AI use as part of your experimental design.
![]()
Want to track your own emissions?
- Python: Try Carbontracker or CodeCarbon, which integrate directly into your pipeline.
- R: Use CarbonR to estimate emissions from statistical models and simulations.
- Heguerte et al. recently uploaded a preprint with some guidelines for how to estimate the footprint when training deep learning models
Written by Patrick Penndorf – LinkedIn
This is a piece from the Sustainability Snack – a weekly educational Newsletter. You can now join for free.
References
Grealey, J., et al., 2022. The carbon footprint of bioinformatics. Mol. Biol. Evol. 39(3), msac034. doi:10.1093/molbev/msac034.
Posani, L., et al., 2019. The carbon footprint of distributed cloud storage. Tech. Rep., Cornell University. arXiv:1803.06973. doi:10.48550/arXiv.1803.06973.
Flagey, N., et al., 2020. Measuring carbon emissions at the Canada–France–Hawaii Telescope. Nat Astron4, 816–818. doi:10.1038/s41550-020-1190-4
Gröger, J., et al., 2021. Green Cloud Computing: Lebenszyklusbasierte Datenerhebung zu Umweltwirkungen des Cloud Computing. Tech. Rep., Umweltbundesamt. Forschungskennzahl 3717 34 348 0.
Luccioni, A.S., Viguier, S., Ligozat, A.-L., 2022. Estimating the carbon footprint of BLOOM, a 176B parameter language model. Tech. Rep., Cornell University. arXiv:2211.02001. doi:10.48550/arXiv.2211.02001.
Dodge, J., et al., 2022. Measuring the carbon intensity of AI in cloud instances. Proc. ACM Conf. Fairness, Accountability, and Transparency (FAccT ’22), 1877–1894. Assoc. Comput. Mach., New York, NY, USA. doi:10.1145/3531146.3533234.
Chien, A. A., et al., 2023. Reducing the carbon impact of generative AI inference (today and in 2035). Proc. 2nd Workshop on Sustainable Computer Systems (HotCarbon ’23), Article 11, 1–7. Assoc. Comput. Mach., New York, NY, USA. doi:10.1145/3604930.3605705.
Hanafy, W. A., et al., 2023. CarbonScaler: Leveraging cloud workload elasticity for optimizing carbon-efficiency. Proc. ACM Meas. Anal. Comput. Syst. 7(3), Article 57, 28 pages. doi:10.1145/3626788.
Adamska, M., et al., 2025. Green prompting. Tech. Rep., Lancaster University. arXiv:2503.10666. doi:10.48550/arXiv.2503.10666.
Lannelongue, L., Inouye, M., 2023. Environmental impacts of machine learning applications in protein science. Cold Spring Harb. Perspect. Biol. 15(12), a041473. doi:10.1101/cshperspect.a041473